Am 3. März, Benutzer ‚llamanon‘ durchgesickert Metas LLaMA-Modell auf 4chans Technologieboard /g/ geleakt, so dass jeder es torren kann.
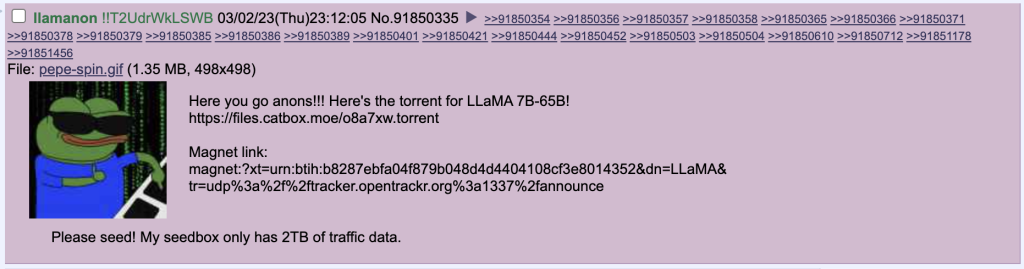
Bevor sich jemand zu aufgeregt, möchte ich betonen, dass LLaMA in der Tat ein Open-Source-Modell ist, das die Leute nur langsam in die Hände bekommen haben.
Vor diesem Hintergrund war das Leck unvermeidlich. Einige Kommentatoren haben sogar spekuliert, dass Meta es zugelassen hat.
Lustigerweise hat ein Troll versucht, die den Torrent-Link hinzuzufügen zum offiziellen LLaMA-Github-Repository von Meta hinzu.
Ich habe einen Nachmittag damit verbracht, die Modellgewichte herunterzuladen und sie zu testen. Hier sind meine Erkenntnisse:
- Die Leute unterschätzen LLaMA. Es ist sehr klug.
- LLaMA scheint nicht clever zu sein, weil es nicht wie ChatGPT auf die Chat-Funktionalität abgestimmt wurde. Seid versichert, Freunde, viele Leute arbeiten daran, während wir hier sprechen.
Es gibt vier verschiedene vortrainierte LLaMA-Modelle mit 7B (Milliarden), 13B, 30B und 65B Parametern.
Meta berichtet, dass das LLaMA-13B-Modell in den meisten Benchmarks besser abschneidet als GPT-3 – das Modell, mit dem ChatGPT arbeitet.
Außerdem wird berichtet, dass das 65B-Modell mit den besten Modellen der Welt mithalten kann, wie zum Beispiel Googles PaLM-540B.
Installation
Im Moment nur Windows und Linux. Hier sind die Anforderungen für jedes Modell:
| Modell | Modell Größe | Minimaler Gesamt-VRAM | Beispiele für Karten | RAM/Swap zum Laden* |
|---|---|---|---|---|
| LLaMA-7B | 3.5GB | 6GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 | 16 GB |
| LLaMA-13B | 6.5GB | 10GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 | 32 GB |
| LLaMA-30B | 15.8GB | 20GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 | 64 GB |
| LLaMA-65B | 31.2GB | 40GB | A100 40GB, 2×3090, 2×4090, A40, RTX A6000, 8000, Titan Ada | 128 GB |
Überprüfe deine technischen Daten, bevor du versuchst, LLaMA auszuführen.
Download Modellgewichte
Erhalte die aktualisierten HFv2-Gewichte, indem du den folgenden Torrent verwendest, oder indem du die ursprünglichen FB-Gewichte konvertierst
Torrent-Datei
Magnet Link
Ich empfehle, zunächst nur das 7B-Modell herunterzuladen.
Microsoft Visual C++ mit Visual Studio 2019 herunterladen
Herunterladen 2019 Visual Studio (dafür musst du dein Microsoft-Konto erstellen und dich anmelden). Es muss die Version 2019 sein.
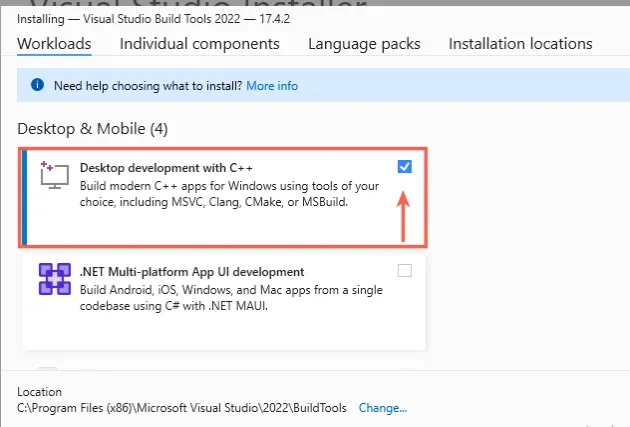
Aktiviere in der Visual Studio-Installation die Option Desktop-Entwicklung mit C++:
Installiere die WebUI von Oobabooga
Oobabooga ist das empfohlene Web-Interface, um deine Sprachmodelle zu verwenden.
Es ist ein bisschen wie die Bilderzeugungs-WebUI AUTOMATIC1111, nur für die Sprache.
Miniconda installieren zuerst, wenn du es noch nicht hast. Die Standardeinstellungen sind in Ordnung.
Öffne eine Eingabeaufforderung/ein Terminal und kopiere diese Befehle und füge sie ein einen nach dem anderennachdem du in das Verzeichnis gewechselt bist, in das du den WebUI-Ordner legen willst.
Gib ein. y um fortzufahren, wenn du dazu aufgefordert wirst, und warte ein paar Minuten, bis die Pakete heruntergeladen sind.
(Möglicherweise musst du conda zu deinem PATH hinzufügen)
conda create -n textgen
conda activate textgen
conda install torchvision torchaudio pytorch-cuda=11.7 git -c pytorch -c nvidia
git clone https://github.com/oobabooga/text-generation-webui
cd text-generation-webui
pip install -r requirements.txtDie dritte Zeile geht davon aus, dass du einen NVIDIA-Grafikprozessor hast.
Wenn du einen AMD-Grafikprozessor hast, ersetze den dritten Befehl durch diesen:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/rocm5.2Wenn du dich entschieden hast, im CPU-Modus zu arbeiten, ersetze den dritten Befehl durch diesen:
conda install pytorch torchvision torchaudio git -c pytorchInstalliere nun GPTQ-for-LLaMa indem du diese Befehle nacheinander kopierst und einfügst (der letzte Befehl ERFORDERT Microsoft Visual C++):
mkdir repositories
cd repositories
git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa
cd GPTQ-for-LLaMa
python setup_cuda.py installLade die Tokenizer/Konfigurationsdateien für die Modellgröße deiner Wahl herunter von decapoda-Forschung:
cd ../..
python download-model.py --text-only decapoda-research/llama-7b-hf
- Platziere das gewünschte LLaMA-Modell, das mit dem neuesten convert_llama_weights_to_hf.py Skript in dein
modelsOrdner. Zum Beispiel,models/llama-7b. - Platziere das entsprechende 4-Bit-Modell direkt in deinem
modelsOrdner. Zum Beispiel,models/llama-7b-4bit.pt. https://huggingface.co/decapoda-research
Konfigurationsschritt nur für Windows
Wenn du unter Windows arbeitest, musst du diesen Schritt ausführen, da du sonst die Fehlermeldung „CUDA nicht gefunden“ erhältst:
Lade die 2 .dll-Dateien herunter hier.
Verschiebe diese 2 Dateien in miniconda3envstextgenlibsite-packagesbitsandbytes
(oder wenn du Anaconda verwendest, anaconda3envtextgenLibsite-packagesbitsandbytes)
Dann öffne den Ordner: miniconda3envstextgenlibsite-packagesbitsandbytescuda_setup
(oder wenn du Anaconda verwendest, anaconda3envtextgenLibsite-packagesbitsandbytescuda_setup)
Rechtsklick > Bearbeiten der main.py mit deinem bevorzugten Texteditor. Nimm diese Änderungen vor:
Ändere ct.cdll.LoadLibrary(binary_path) in ct.cdll.LoadLibrary(str(binary_path)) zwei Mal in der Datei.
Ersetze dann die Zeile:
if not torch.cuda.is_available(): return 'libsbitsandbytes_cpu.so', None, None, None, None
mit:
if torch.cuda.is_available(): return 'libbitsandbytes_cuda116.dll', None, None, None, None
Jetzt kannst du Modelle mit 8-Bit-Präzision unter Windows ausführen.
Start
Lege das Modell, das du im ersten Schritt heruntergeladen hast, in den Ordner text-generation-webui/models.
Jetzt kannst du die WebUI starten:
python server.py --load-in-4bit --model llama-7b-hf
Ersetze aber llama-7b-hf durch den Ordnernamen des Modells. Es kann eine Weile dauern, bis das Modell geladen ist. Als Referenz, ich

Warte auf die Erfolgsmeldung und dann kannst du loslegen!
Öffne die WebUI, indem du navigierst zu
http://localhost:7860/
Thread zur Fehlerbehebung: https://github.com/oobabooga/text-generation-webui/issues/147
Fehlersuche unter Windows: https://github.com/oobabooga/text-generation-webui/issues/20
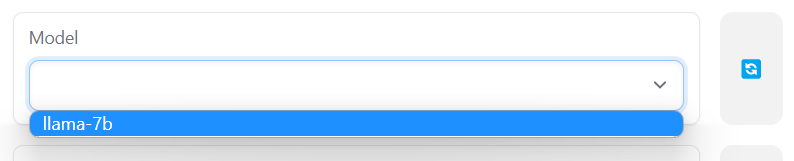
Stelle sicher, dass du nach unten scrollst und das Modell in das LLaMA-Modell änderst:
0 Kommentare